











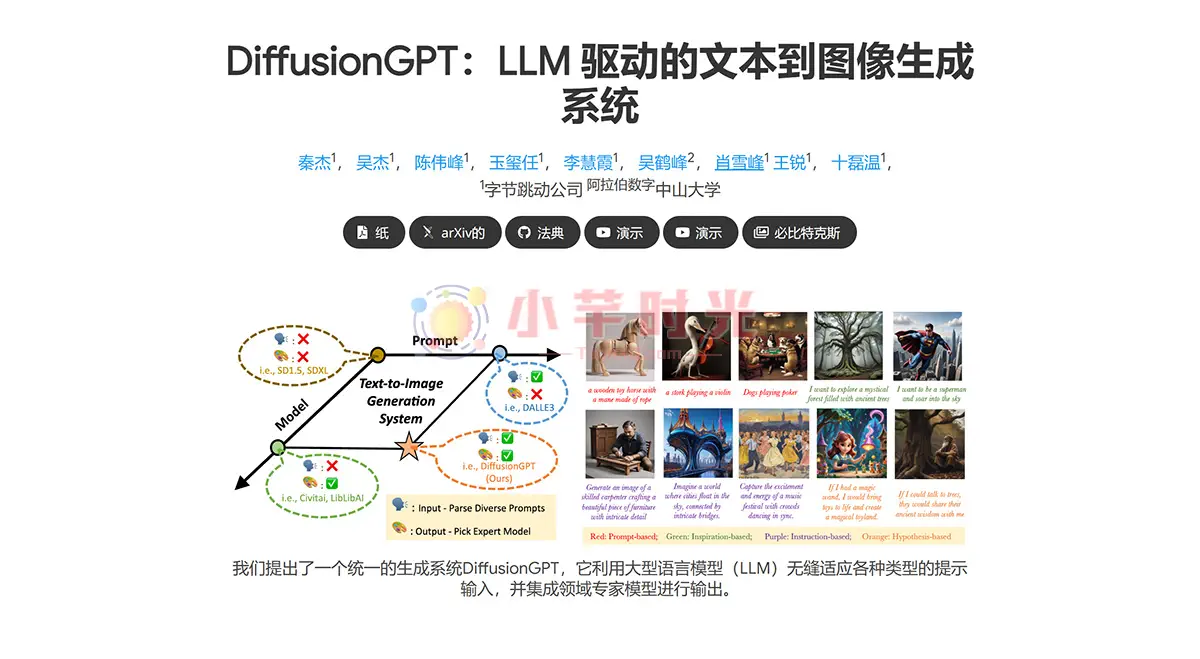
DiffusionGPT简介
DiffusionGPT是字节跳动推出的一种多功能图像生成系统,采用大型语言模型(LLM)为核心驱动力,专门设计来根据各种文字输入提示生成高质量图像。系统的核心目的在于分析输入提示,随后确定哪种生成模型能够带来最佳的成像效果。特点是高度泛化性、效率以及用户友好性。
DiffusionGPT 的强大之处在于它能集成并运用多个专家级图像生成模型,由 LLM 负责处理和解析各种文本提示,根据这些信息选择最适合当前请求的图像模型来制作图像,形成了一个能够根据对话内容创造图像的系统,类似于GPT-4的工作方式。
DiffusionGPT主要特点:
1. 多元文本提示处理能力:无论是具体的命令、抽象的灵感还是更复杂的假设性文本,DiffusionGPT都能提供理解和处理。
2. 多专业领域图像模型集成:系统整合了自然风光、肖像画、艺术品等不同领域的图像扩散模型,每一模型在所属领域都具备出色的图像创造能力。
3. LLM导向:类似GPT-4的语言模型用于分析和理解用户输入,专门针对图像生成的指令和描述进行处理。
4. 智能化模型选择:DiffusionGPT基于输入文本的理解智能选取应用最合适的图像生成模型,并调整参数以满足用户需要。
5. 高质量图像输出:精准结合文本提示与图像模型,输出高质量、符合用户期望的图像。
6. 用户反馈结合:采用用户的反馈不断优化模型选择,提高图像产出的相关性和质量。
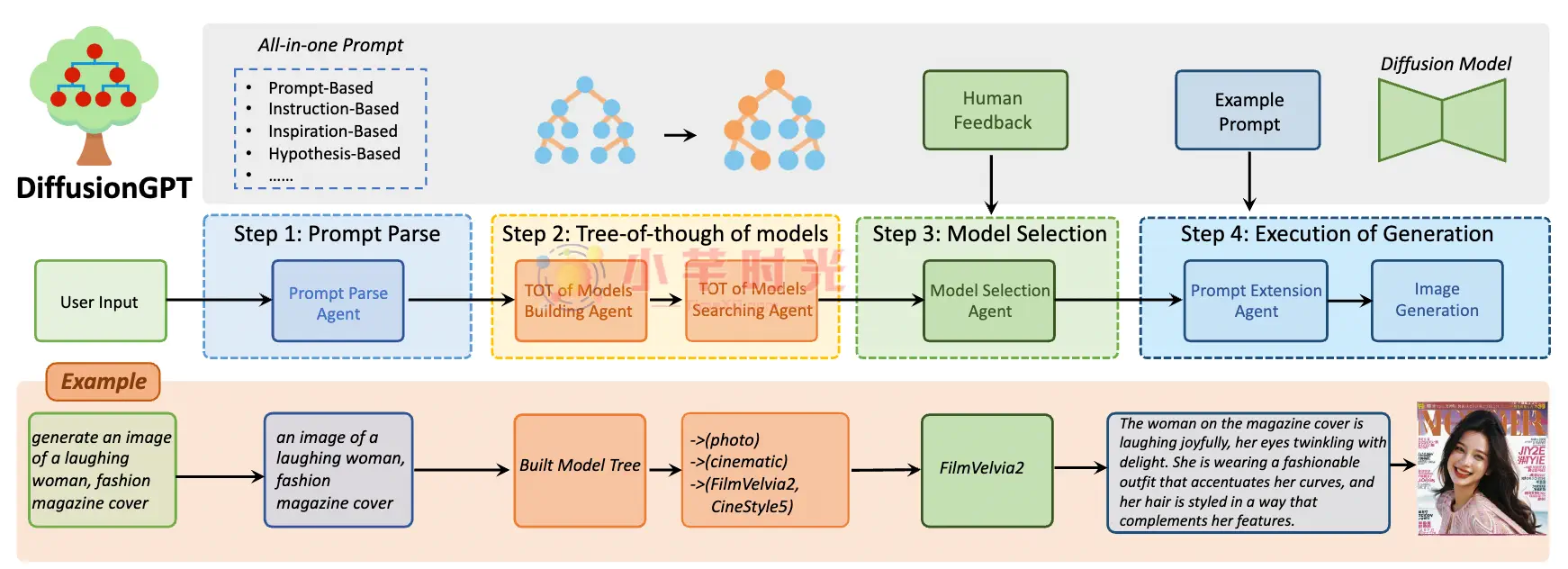
DiffusionGPT工作流程:
1. 输入解析:用户通过描述、指令或灵感进行文本输入。
2. 语言理解:LLM分析文本含义和需求。
3. 思维树构建:构筑不同图像模型的组织结构,便于从中选择合适的模型。
4. 模型选择:基于优势数据库和用户反馈,系统遴选最适合所给文本提示的生成模型。
5. 图像生成实施:选定模型生成与提示紧密相关的图像,反映用户意图。
6. 用户反馈利用:生成图像后,用户反馈帮助优化模型数据库,改进未来图像生成。
DiffusionGPT已经在生成各类图像,如人物肖像和现实场景等方面证明了其高度的细节与真实感。它生成的图像在视觉保真度和细节捕捉方面优于多数基线模型。同时,在用户满意度和美学评分上也表现出比传统扩散模型更优的性能。这些评分结果表明,DiffusionGPT生成的图像在质量和美观程度上更受用户青睐。
数据评估
本站小芊时光提供的DiffusionGPT-文本生成图像多合一系统都来源于网络,不保证外部链接的准确性和完整性,同时,对于该外部链接的指向,不由小芊时光实际控制,在2024年4月18日 上午10:33收录时,该网页上的内容,都属于合规合法,后期网页的内容如出现违规,可以直接联系网站管理员进行删除,小芊时光不承担任何责任。



