











CogVideo详细解析
CogVideo,由清华大学和BAai唐杰团队提出,是一款开创性的通用领域文本到视频生成的预训练模型,拥有94亿个参数。该模型在GitHub上开源,吸引了大量关注,并因其先进的技术性能而备受瞩目。
其核心优势在于将预训练的文本到图像生成模型CogView2的机制扩展到视频领域,通过多帧率分层训练策略,CogVideo能够从文本描述中生成动态且写实的视频序列。这一训练策略使得模型能够以高效的方式产生视频,并能在保持细节丰富度的同时合成连贯的场景动态。
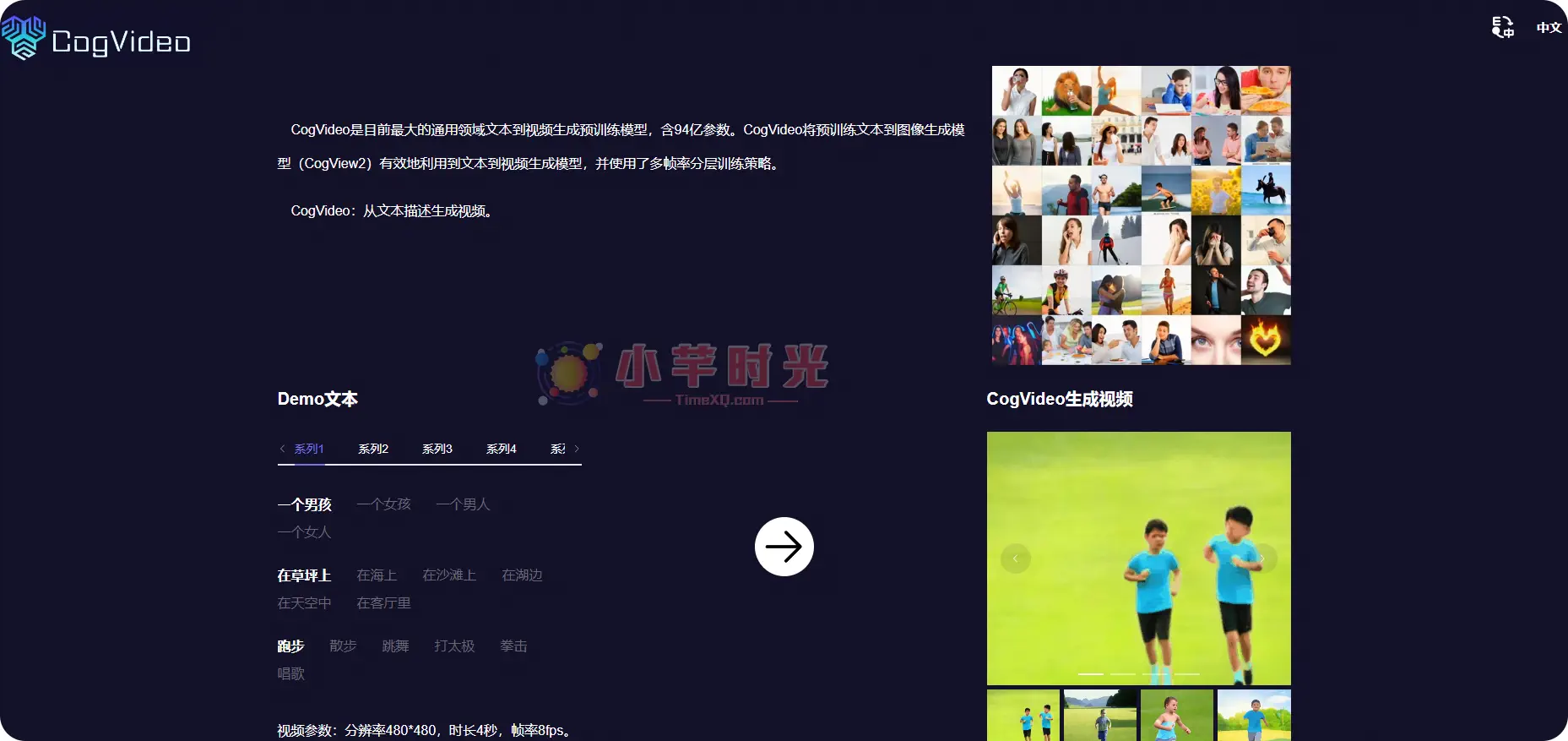
训练过程分为两个步骤:首先,它利用CogView2从提供的文本中生成关键帧图像;随后,模型通过插帧技术提高帧率,从而完成整个视频的生成。这种多帧生成的方法能够更好地捕捉并延续文本的语义内容至动态视觉展示,让视频在语义上与文本描述保持紧密对应。
除了英文输入的能力外,CogVideo还特别优化了中文输入,并通过提供完整的文档和实用的教程,使模型更加易于用于各种研究和开发场景。它的开发者友好特性和开源性质使其在视频内容理解和生成等多模态AI研究领域中扮演着关键角色。
CogVideo的开发不仅推动了视频内容生成技术的发展,而且为创意产业的变革带来了无限可能。该模型打开了一扇门,探索了从文字描述到动态视频内容的直接转换,这对于影视创作、游戏开发、虚拟现实以及教育领域等多个行业均有着深远的影响。
综上所述,CogVideo作为一种先进的文本到视频生成模型,展示了在使用预训练模型生成高质量视频的能力。然而,随着生成视频过程中仍存在的挑战,如有限的文本到视频数据集和复杂动态语义理解的难度,该领域依旧需要持续的研究和开发来提升模型的表现和适用性。
数据评估
本站小芊时光提供的CogVideo-文本生成视频预训练模型都来源于网络,不保证外部链接的准确性和完整性,同时,对于该外部链接的指向,不由小芊时光实际控制,在2024年4月15日 上午10:10收录时,该网页上的内容,都属于合规合法,后期网页的内容如出现违规,可以直接联系网站管理员进行删除,小芊时光不承担任何责任。





